Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
12.5-rc-1
-
None
-
Mozilla Firefox 91.0 and Google Chrome 92.0.4515.159
-
Unit
-
Unknown
-
N/A
-
N/A
-
Description
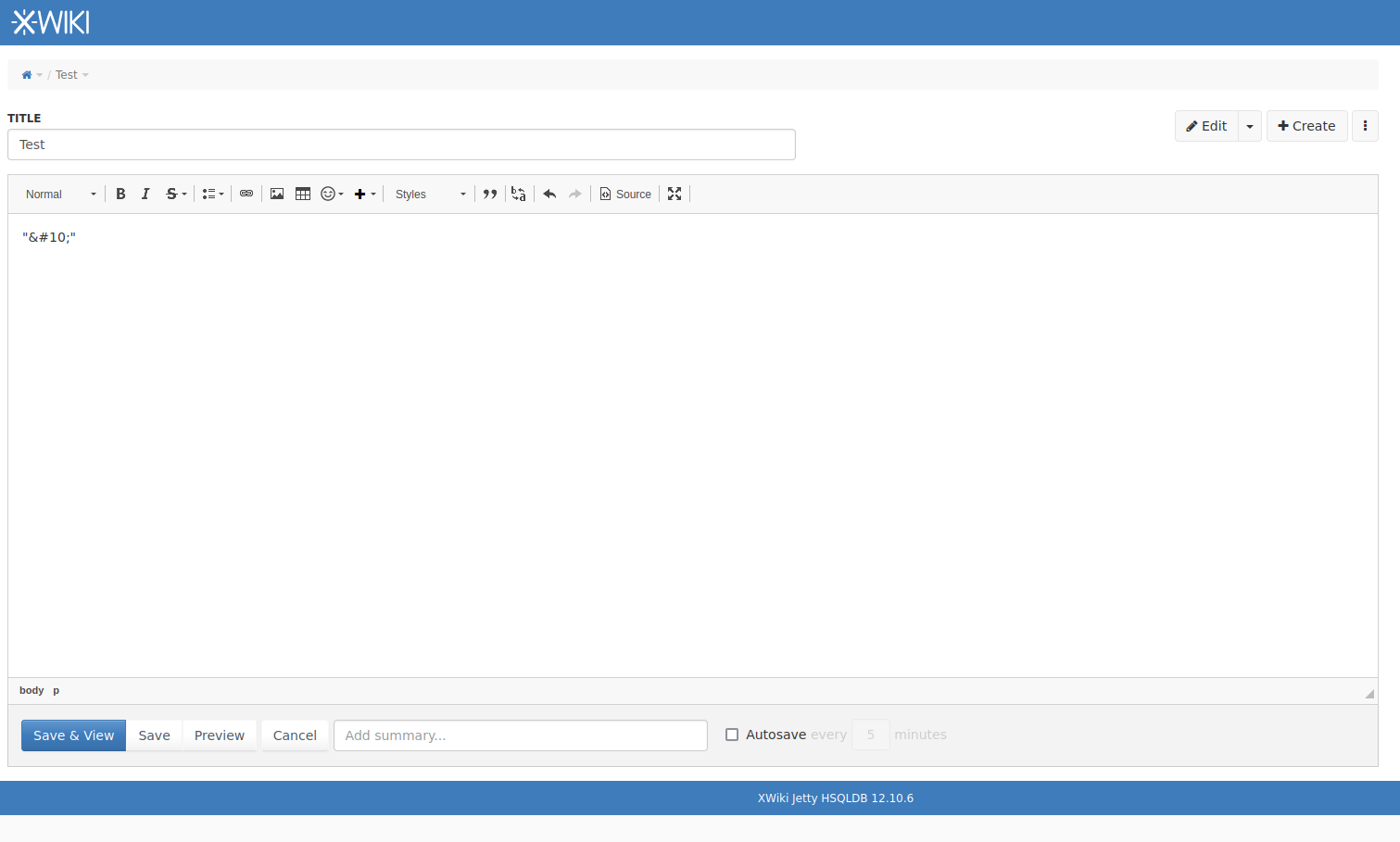
Steps to reproduce:
- Add a HTML Encoded Line Feed character like
or


.etc, in WYSIWYG editor
- Save the page
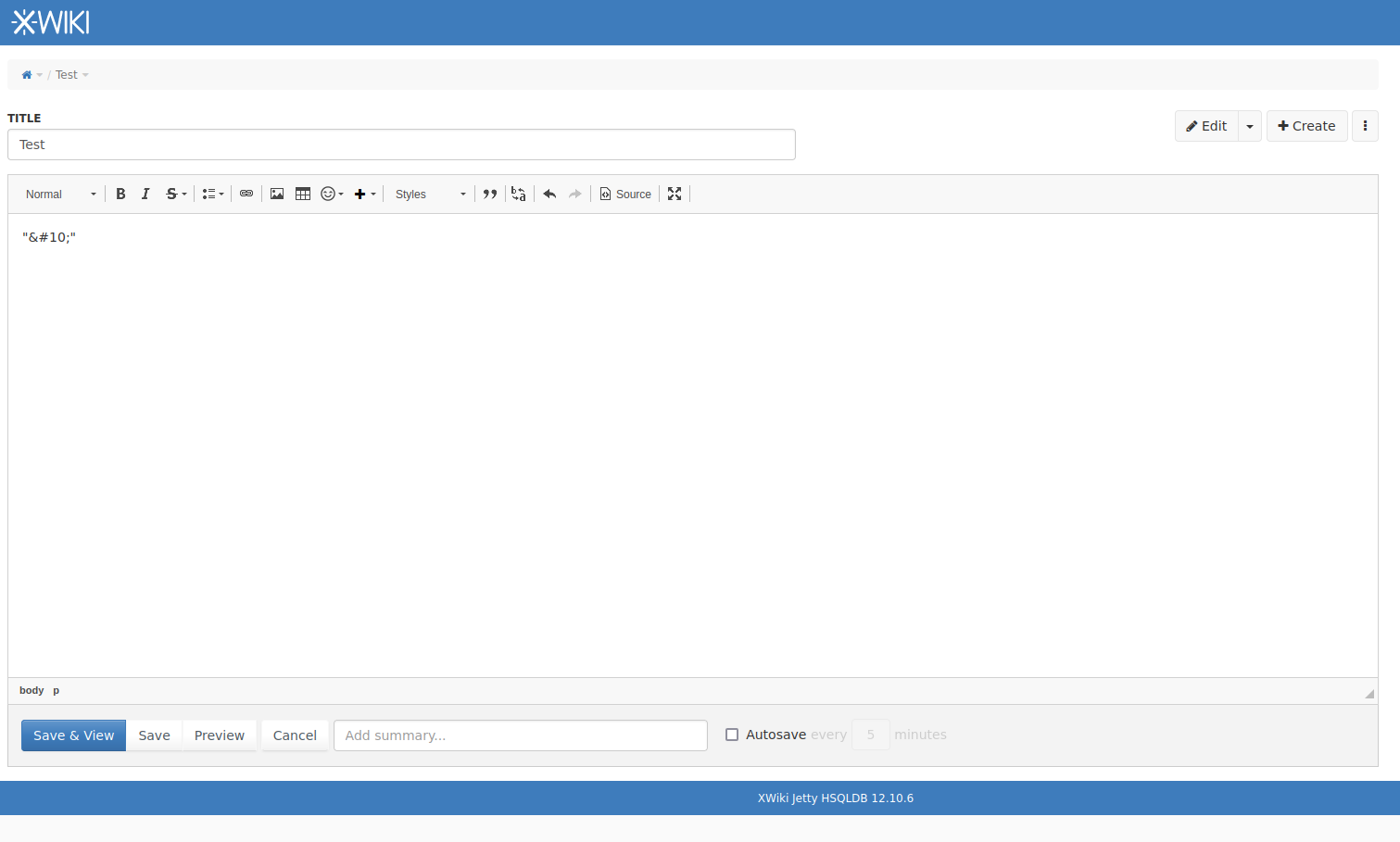
Expected results:
- The character is displayed after the page is saved in WYSIWYG editor.
Results:
- The character is transformed in a whitespace / non-breaking space
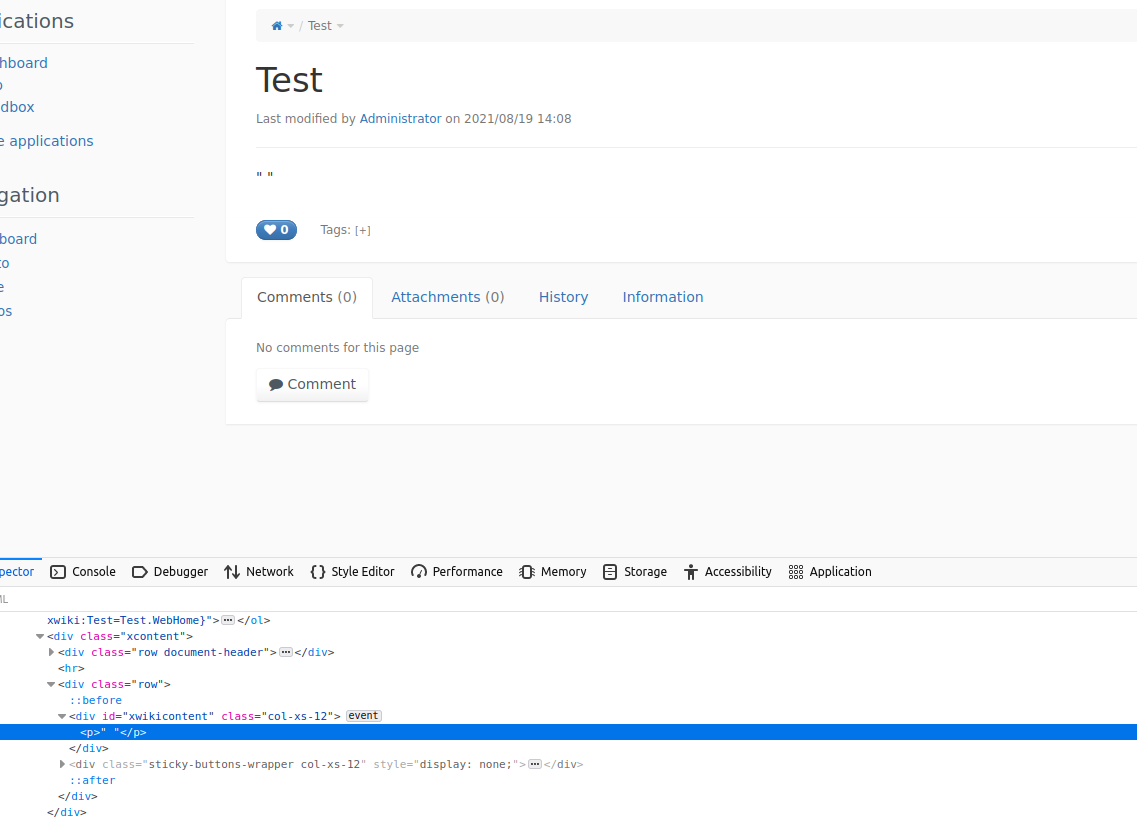
Saving the page in Wiki editor or in WYSIWYG editor while in source mode the character is not transformed.
Attachments
{kind=link}
{kind=link}
Issue Links
- is related to
-
XCOMMONS-1938 Upgrade to HtmlCleaner 2.24
-
- Closed
-
- relates to
-
-
- Closed
-