Details
-
Improvement
-
Resolution: Fixed
-
 Major
Major
-
5.1-milestone-2
Description
The idea is:
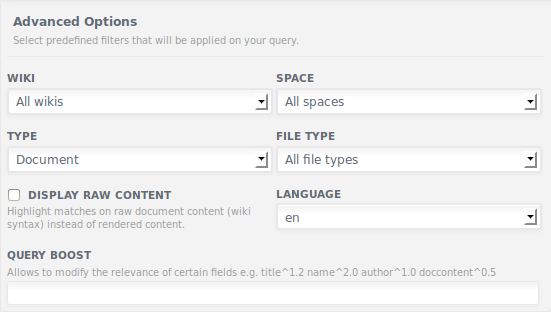
- By default display search results for doccontent only
- Have an advanced search checkbox to display doccontentraw results
Attachments
Issue Links
- is duplicated by
-
XWIKI-9271 Result should show extract too
-
- Closed
-